




Meta, the company behind the open-source Llama family of AI models, unveiled a new report on Monday titled ‘The Frontier AI Framework’.
This report outlines the company’s approach to developing general-purpose AI models by evaluating and mitigating their “catastrophic risks”. It focuses on large-scale risks, such as cybersecurity threats and risks from chemical and biological weapons.
“By prioritising these areas, we can work to protect national security while promoting innovation,” read a blog post from the company announcing the report.
The framework is structured around a three-stage process: anticipating risks, evaluating and mitigating risks, and deciding whether the model should be released, restricted, or halted.
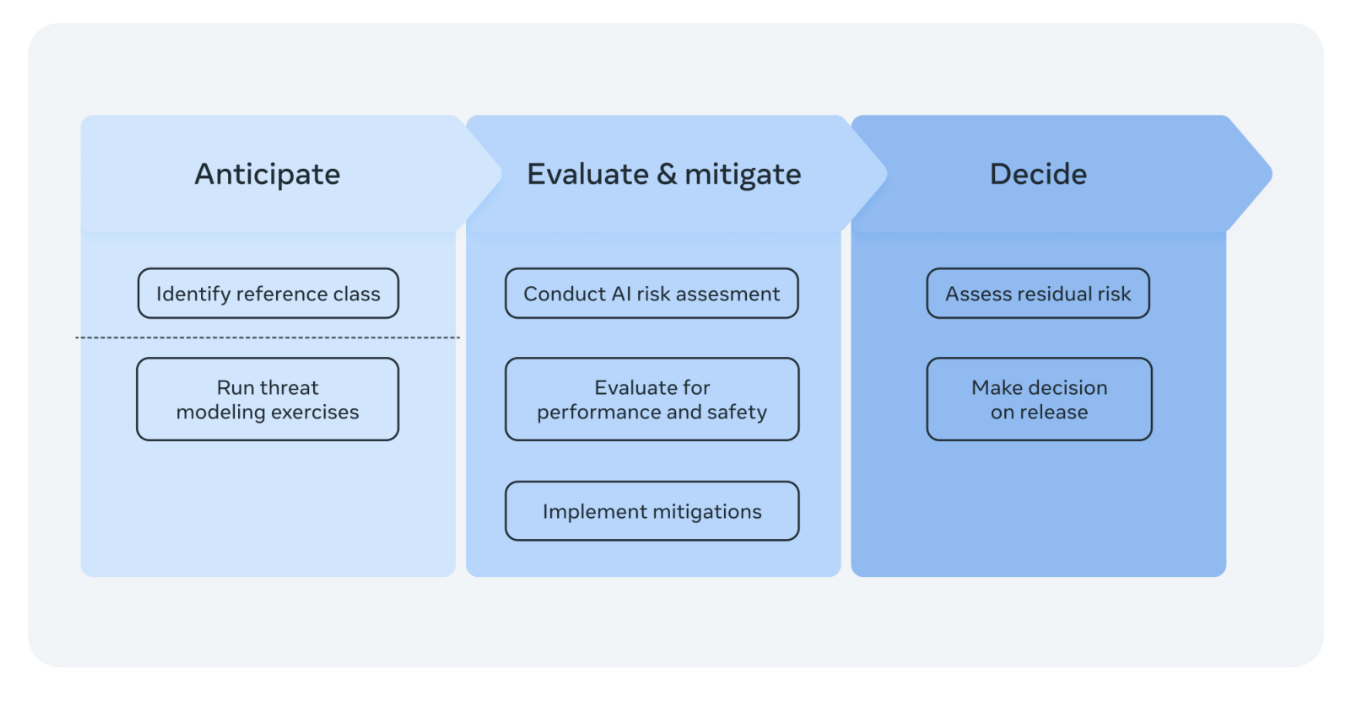
The report contains risk assessments from various experts in multiple disciplines, including engineering, product management, compliance and privacy, legal and policy, and other company leaders.
If the risks are deemed “critical”, the framework suggests stopping the development of the model and restricting access to a small number of experts with security protections.
If the risks are deemed “high”, the model should not be released but can be accessed by a core research team with security protections. Lastly, if the risks are “moderate”, the model can be released as per the framework.
It is recommended that you read the full report to understand each of these risk levels in detail.
“While it’s not possible to entirely eliminate risk if we want this AI to be a net positive for society, we believe it’s important to work internally and, where appropriate, with governments and outside experts to take steps to anticipate and mitigate severe risks that it may present,” the report stated.
Multiple companies building AI models have unveiled such frameworks over the years. For instance, Anthropic’s ‘Responsible Scaling Policy’ provides technical and organisational protocols that the company is adopting to “manage risks of developing increasingly capable AI systems”.
Anthropic’s policy defines four safety levels. The higher the safety level, the larger the model’s capability, which increases security and safety measures.
In October last year, the company said it was required to upgrade its security measures to an AI safety level of 3, which is the penultimate level of safety. This level suggests that the model’s capability poses a “significantly higher risk”.
Similarly, OpenAI has a charter that outlines its mission to develop and deploy AI models safely. Furthermore, the company regularly releases a system card for all of its models, which outlines its work regarding safety and security before releasing any new variant.
























